
Haskell numeric types: quick reference

Num
class Num a
(+), (*), (-), abs, signum, fromInteger, (negate | (-))Real
class (Num a, Ord a) => Real
toRationalFractional
class Num a => Fractional a
(/), recip, fromRationalIntegral
class (Real a, Enum a) => Interal a
quot, rem, div, mod, quotRem, divMod, toIntegerRealFrac
class (Real a, Fractional a) => RealFrac a
properFraction, truncate, round, ceiling, floorFloating
class Fractional a => Floating a
pi, exp, sqrt,
log, (**), logBase,
sin, tan, cos,
asin, atan, acos,
sinh, tanh, cosh,
asinh, atanh, acoshRealFloat
class (RealFrac a, Floating a) => RealFloat a
floatRadix, floatDigits, floatRange,
decodeFloat, encodeFloat, exponent,
significand, isNaN, isInfinite,
isDenormalized, isNegativeZero, isIEEE,
atan2 Convert hs to lhs
hs2lhs
tl;dr Here is the code to convert hs to lhs
Often I decide to write a blog post based on some haskell code that I have already written in normal (.hs) form. Had I known before writing the code that it would become a blog post I would have written it using the literate haskell (.lhs) format. So I wrote this small program to convert .hs to .lhs
Although the script is short (probably over golfed), it does demonstrate some nice haskell features.
Overloaded Strings and Data.Text
The ghc OverLoadedStrings language extension allows you to use string literals as text literals so you don’t have to convert String to Text.
> {-# LANGUAGE OverloadedStrings #-}
Multi-way if-expressions
Multi-way if-expressions allow the use of the guard syntax we commonly see for top level functions in if statements:
if | cond1 -> expr1
| cond2 -> expr2
...
| condn -> exprn> {-# LANGUAGE MultiWayIf #-}
> module Main where
>
> import Control.Applicative ((<$>), (<|>))
> import Data.Maybe (fromMaybe)
> import Data.Text (Text, stripStart, stripPrefix,
> isPrefixOf, isSuffixOf)
> import qualified Data.Text as T
> import qualified Data.Text.IO as T
> import System.Environment
In order to handle line breaks, we need to keep track of whether or not the last line parsed was a comments or code.
> data Tag = Comment | Code
Applicative and Alternative
The core of the program is the lhsLine function which converts each line in the .hs file to a line in the .lhs file and keeps track of the Tag. The stripPrefix function from Data.Text returns the input text stripped of a prefix as a Maybe value. It returns Nothing if the prefix does not match beginning of the text. We use fmap (<$>) to pair this result with its Tag inside the Maybe and the Alternative instance of Maybe (<|>) to choose the first Just value (or Nothing) if neither alternative matches.
> lhsLine :: Tag -> Text -> (Tag, Text)
> lhsLine w t = fromMaybe d c
> where
> d = if | t == T.empty -> (Code, "")
> | isPrefixOf "{-#" t &&
> isSuffixOf "#-}" t -> (Code, "> " `T.append` t)
> | otherwise -> (Code, s `T.append` t)
> s = case w of {Comment -> "\n> "; Code -> "> "}
> c = stripC "-- |" t <|> stripC "--" t
> stripC p t = (\x -> (Comment, stripStart x)) <$> stripPrefix p t
We could use the State monad but it would be overkill. Simply threading the state (Tag) through as an argument is fine.
> lhs :: Tag -> [Text] -> [Text]
> lhs _ [] = []
> lhs c (t:ts) = t' : (lhs c' ts)
> where (c', t') = lhsLine c t
> main = do
> text <- T.readFile . head =<< getArgs
> let p = T.lines text
> mapM_ T.putStrLn (lhs Code p)
Give it a try!
Solving the 15-Puzzle with Haskell and diagrams
Something I like to do when learning a new programming language is to code a familiar project. This lets me gauge my progress and make comparisons with languages I’m more comfortable with. One of my favorite “familiar” projects is a solver for the 15-puzzle. If you’re not familiar with the 15-puzzle, it’s a classic grid based game with 4 rows and 4 columns containing a total of 15 tiles. The tiles are labeled 1-15 and there is one blank space. The object is to put the tiles in ascending order by repeatedly sliding a tile into the blank space. See 15 puzzle.

45 move puzzle
There’s a reason the 15 puzzle has become a favorite coding exercise of mine. Its solution is a particularly nice example of the interplay between algorithms and data structures. In particular, we use the A* algorithm which relies on a priority queue.
While studying Haskell and working on the diagrams project I decided that I could take my 15 puzzle solution to the next level, by using diagrams to animate it.
We start by getting the imports out of the way.
> module Main where
>
> import Data.Array.Unboxed
> import Data.List (elemIndex)
> import Data.List.Split (chunksOf)
> import Data.Maybe (mapMaybe)
> import qualified Data.PQueue.Prio.Min as PQ
> import Diagrams.Prelude
> import Diagrams.Backend.Rasterific.CmdLine
> import System.Environment
Creating the animated GIF
Next, lets write the diagrams code to draw and animate a solution assuming we have already solved a 15 puzzle. The solution takes the form [Board] where Board is a matrix of tiles. Each tile is a number between 1 and 15.
> type Board = UArray (Int, Int) Int
First we need to draw a single Board, i.e convert it to a diagram. Our strategy is to map a function that draws each tile onto the board, then concatenate the tile diagrams into a diagram of the puzzle board. diagrams has built in functions for vertically and horizontally concatenating lists of diagrams so we start by converting the Board to a list.
> fromBoard :: Board -> [[Int]]
> fromBoard b = [row i | i <- [1..n]]
> where
> row i = [b ! (i, j) | j <- [1..n]]
> n = dim b
The number of rows and columns in the puzzle is the upper bound of the array since we are using 1 (not 0) as the starting indices for our array.
> dim :: Board -> Int
> dim = snd . snd . bounds
Assuming we have a function drawTile that makes a number into a tile diagrams we can now create a diagram from a game board.
> boardDia :: Board -> Diagram B R2
> boardDia b = bg gray
> . frame 0.1
> . vcat' (with & sep .~ 0.075)
> . map (hcat' (with & sep .~ 0.075))
> . (map . map) drawTile $ fromBoard b
Here is drawTile
> drawTile :: Int -> Diagram B R2
> drawTile 0 = square 1 # lw none
> drawTile s = text (show s)
> # fontSize (Local 1)
> # fc white
> # scale 0.5
> # bold
> <> roundedRect 1 1 0.2
> # fc darkred
Now we need to assemble a bunch of board diagrams into a GIF. All we need to do is pass a list of diagrams and delay times [(Diagram B R2, Int)] to the mainWith function, choose a .gif file extension when we run the program and diagrams will make an animated GIF.
> dias :: [Board] -> [Diagram B R2]
> dias bs = map boardDia bs
We show each board for 1 second and pause for 3 seconds before repeating the GIF loop.
> times :: Int -> [Int]
> times n = replicate (n-1) 100 ++ [300]
> gifs :: [Board] -> [(Diagram B R2, Int)]
> gifs bs = zip (dias bs) (times . length $ bs)
Here is an example main program that solves a puzzle read in from a text file. The format of the puzzle file has as first line a single integer representing the dimension of the puzzle and each additional line a string of integers representing a row of the starting puzzle board. For example the puzzle at the top of the post has file:
4
9 2 8 11
0 5 13 7
15 1 4 10
3 14 6 12To run the program type the the following at the command line and then enter the path to your puzzle file: ./Puzzle -o my_solution.gif -w 300
Of course we still need to write, solve, mkGameState, and boards.
> main = do
> putStrLn "Enter the name of the file containing the puzzle:"
> txt <- readFile =<< getLine
> let game = fromString txt
> ([n], brd) = case game of
> [] -> error "Invalid puzzle file"
> x:xs -> (x, concat xs)
> let p = solve . mkGameState n $ brd
> mainWith $ gifs (boards p)
> fromString :: String -> [[Int]]
> fromString s = (map . map) read ws
> where ws = map words (lines s)
The A* algorithm
We are going to search for a solution using the A* algorithm. We will keep track of the state of the game in an algebraic data type called GameState.
The game state includes the board, the number of moves up until this point and a previous state (unless this it the start state). We also cache the location of the blank tile and the manhattan distance to the goal state; so that we only need to calculate these things once.
Notice that GameState recursively contains the game state that preceded it (wrapped in a Maybe) , except for the start state whose previous field will contain Nothing. This will allow us recreate all of the intermediate boards from the final solved board so that we can animate the game. We use the boards function to create the list containing each board from start to finish.
> data GameState = GameState
> { board :: Board
> , dist :: Int
> , blank :: (Int, Int)
> , moves :: Int
> , previous :: Maybe GameState
> } deriving (Show, Eq, Ord)
> boards :: GameState -> [Board]
> boards p = reverse $ brds p
> where
> brds q = case previous q of
> Nothing -> [board q]
> Just r -> board q : brds r
The possible moves.
> data Direction = North | East | South | West
We create a priority queue Frontier whose priorities are the sum of the moves made so far to reach the game state and the manhattan distance to the goal state. This is an admissible heuristic function which guarantees that the solution we find will take the minimum number of moves. The initial Frontier contains only the start state. Then we recusively pop the minimum game state from the queue and check to see if it is the goal, if it is we are done, if not we calculate the states reachable by a legal game move (neighbors) and add them to the queue. Here’s the code.
> type Frontier = PQ.MinPQueue Int GameState
Manhattan distance of a tile with value v at position (i, j), for a game of dimension n.
> manhattan :: Int -> Int -> Int -> Int -> Int
> manhattan v n i j = if v == 0 then 0 else rowDist + colDist
> where
> rowDist = abs (i-1 - ((v-1) `div` n))
> colDist = abs (j-1 - ((v-1) `mod` n))
Manhattan distance of entire board.
> totalDist :: Board -> Int
> totalDist b = sum [manhattan (b ! (i, j)) n i j | i <- [1..n], j <- [1..n]]
> where n = dim b
Create a start state from a list of tiles.
> mkGameState :: Int -> [Int] -> GameState
> mkGameState n xs = GameState b d z 0 Nothing
> where
> b = listArray ((1, 1), (n, n)) xs
> d = totalDist b
> Just z' = elemIndex 0 xs
> z = (1 + z' `div` n, 1 + z' `mod` n)
Update the game state after switching the position of the blank and tile (i, j).
> update :: GameState -> Int -> Int -> GameState
> update p i j = p { board = b
> , dist = totalDist b
> , blank = (i, j)
> , moves = moves p + 1
> , previous = Just p }
> where
> b = b' // [(blank p, b' ! (i, j)), ((i, j), 0)]
> b' = board p
Find the the board that can be reached from the current state by moving in the specified direction, being careful not to move off the board.
> neighbor :: GameState -> Direction -> Maybe GameState
> neighbor p dir = case dir of
> North -> if i <= 1 then Nothing else Just $ update p (i-1) j
> East -> if j >= n then Nothing else Just $ update p i (j+1)
> South -> if i >= n then Nothing else Just $ update p (i+1) j
> West -> if j <= 1 then Nothing else Just $ update p i (j-1)
> where
> (i, j) = blank p
> n = dim . board $ p
All of the states that can be reached in one move from the current state.
> neighbors :: GameState -> [GameState]
> neighbors p = mapMaybe (neighbor p) [North, East, South, West]
Finally, solve the puzzle.
> solve :: GameState -> GameState
> solve p = go (PQ.fromList [(dist p, p)])
> where
> go fr = if dist puzzle == 0
> then puzzle
> else go fr2
> where
> -- Retrieve the game state with the lowest priority and > -- remove it from
> -- the frontier.
> ((_, puzzle), fr1) = PQ.deleteFindMin fr
>
> -- If the new board is the smae as the previous board then
> -- do not add it to the queue since it has already been > -- explored.
> ns = case previous puzzle of
> Nothing -> neighbors puzzle
> Just n -> filter (\x -> board x /= board n)
> (neighbors puzzle)
>
> -- The priority of a puzzle is the number of moves so far
> -- plus the manhattan distance.
> ps = zip [moves q + dist q | q <- ns] ns
> fr2 = foldr (uncurry PQ.insert) fr1 ps
You can find more puzzles in my github repo: puzzles. Happy solving !
Monkey typing ABRACADABRA
Since I decided to call this blog martingalemeasure it seems only fitting that the first post should be about probability; martingales in particular. In my favorite introductory book on measure theoretical probability, “Probablity with Martingales” by David Williams, we find an exercise in Chapter 10, which I paraphrase here:
Suppose a monkey is typing randomly at a typewriter whose only keys are the capital letters 


This is not an easy problem. In fact it’s not entirely obvious that the average time is even finte! Williams expects the reader to solve it using the beautiful theory of martingales and in particular Doob’s optional-stopping theorem. We will calculate the result below, but stop short of a proof. (There are many proofs of this result already on the web. A quick search for “monkey abracadabra” will provide several links).
The purpose of this post is to try to provide the intuition behind the result. We do this by comparing the expected time it takes for the monkey to type 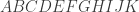
Simplification
It’s almost always a good idea when trying to solve a problem to first attack the simplest case you can think of that still embodies the essence of the problem. For our problem we can certainly benefit both from picking shorter strings, and by choosing a smaller alphabet. The important distinction between 
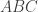


Solution
Ok, let’s use martingale theory to solve the simplified problem and then apply the result to the bigger problem. As is often the case in probability theory we will think in terms of gamblers making bets. Suppose that just before each keystroke made by the monkey, a new gambler shows up at a casino and employs the following betting strategy. She wagers one dollar that the monkey will type an 
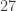

Each individaul bet is fair, that is, has an expected value of zero. Indeed, our gambler has a 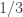

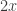

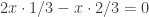
Here comes the big trick, when we say that the casino has expected gains of zero at any time, we mean random times as well. Including random times like 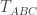


![\displaystyle \mathbb{E}[T_{ABC} - 27]=0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5BT_%7BABC%7D+-+27%5D%3D0&bg=ffffff&fg=333333&s=0&c=20201002)
Hence, by the linearity of expectation,
![\displaystyle \mathbb{E}[T_{ABC}]=27](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5BT_%7BABC%7D%5D%3D27&bg=ffffff&fg=333333&s=0&c=20201002)
But what happens when we analyze the string
![\displaystyle \mathbb{E}[T_{ABA}-27-3]=0](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5BT_%7BABA%7D-27-3%5D%3D0&bg=ffffff&fg=333333&s=0&c=20201002)
and
![\displaystyle \mathbb{E}[T_{ABA}]=30](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5BT_%7BABA%7D%5D%3D30&bg=ffffff&fg=333333&s=0&c=20201002)
Wow, the average time for the monkey to type
Back to ABRACADABRA
It should now be straight forward to calculate the expected time it takes for the monkey to type 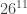

![\displaystyle \mathbb{E}[T]=26^{11} + 26^4 + 26](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cmathbb%7BE%7D%5BT%5D%3D26%5E%7B11%7D+%2B+26%5E4+%2B+26&bg=ffffff&fg=333333&s=0&c=20201002)
Intuition
I don’t know about you, but I find this result is counter-intuitive. I expected it would take the same time on average, or if anything shorter to type
A B C * *
* A B C *
* * A B CIf we want to know the probability that the monkey typed 


A B A * *
* A B A *
* * A B AAnd again the probability of each event is 
A B A B AAnd that is the only string that they have in common. So by the inclusion – exclusion principle we need to subtract that case out to get the probability as 

And now it should be clear why the average time for the monkey to type a word is longer if the word has repeated sub-strings. For any given time the probability of typing the string with repeated sub-strings is lower so it must take longer on average for the event to happen.
